|
|
G16两个版本的效率比较。没啥惊天动地的内容,就是分享给大家看看,在版本区别核和并行效率上 心里有数。
原文:http://computational-chemistry.c ... ussian16-benchmark/
Gaussian 16 was released early in 2017. A binary compatible with the AVX 2 extended instruction set has been newly available. Also, with the corporation of Gaussian, Nvidia and PGI, GPGPU is now available for DFT calculation and HF calculation.
In order to grasp the fundamental performance of Gaussian 16, we got a benchmark on workstation with Haswell microarchitecture. The calculation contents are the comparison of Structural Optimization and Frequency calculation in DFT under realistic condition, and the comparison with Gaussian09 using test397 input.
As a result of benchmarking, the calculations with B3LYP/6-31G(d,p) basis set were performed at 44 cores, opt was over in 2.7 hours and Freq was over in 3.5 hours. In addition, since the default calculation accuracy got higher in test 397, it gave a slower result than Gaussian 09, but we confirmed that the AVX 2 version greatly contributes to speed improvement.
EnvironmentCPU: Intel Xeon E5-2699 v4 * 2CPU (total 44core)
Memory: DDR4 128GB 2400MHz
HDD: 1TB SATA6Gbps 10000rpm
OS: Fedora25
Gaussian 16 used for the benchmark is a Gaussian standard Binary version package optimized for AVX2. Gaussian 09 to be compared with is a Gaussian standard Binary package optimized for AVX.
ResultThe result is as follows.
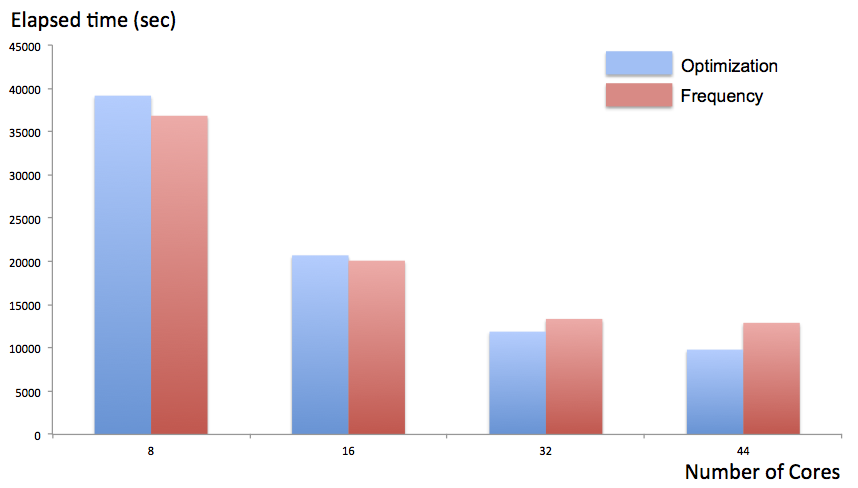
In the optimization, 34 iterations were executed.
![]()
In the Optimization calculation, we confirmed the calculation speed improvement by scaling to 44 cores (thread) which is the maximum parallel number of the CPU used this time in no way inferior.
Although parallelization efficiency (strong scalability) is lower than that of Opt calculation, Freq calculation also improved to 44 parallels.
![]()
In the case of Opt & Freq calculation by DFT, we recommended to use up to 32 cores.
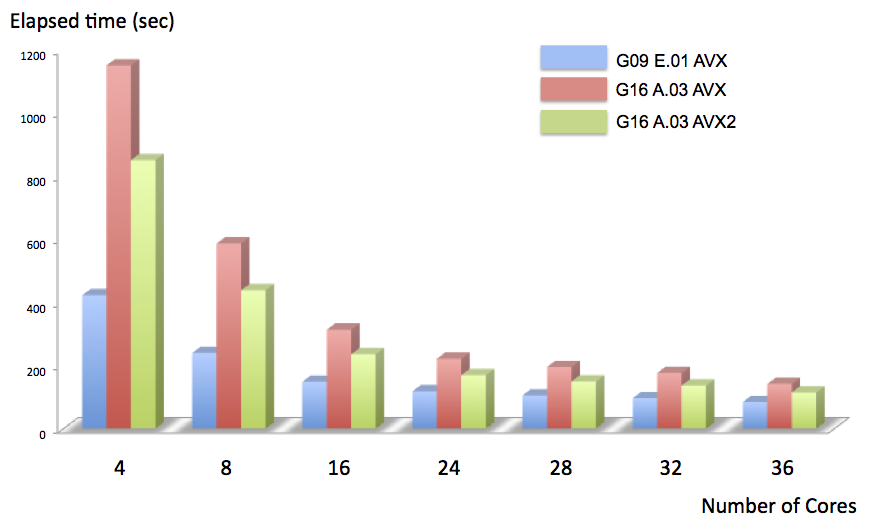
Next, we compared g09_AVX, g16_AVX and g16_AVX2.
g09_AVX vs g16_AVX vs g16_AVX2![]()
Compared to the AVX version of Gaussian 09, the AVX version of Gaussian 16 is slower. This is because that in order to guarantee the calculation accuracy of several new calculation types (eg, TD-DFT frequency and anharmonic ROA, etc.) in Gaussian 16, the default integration accuracy was improved from ![]() to to ![]() , and also the default DFT grid has been changed from FineGrid to UltraFine. On the other hand, the newly supported AVX2 version of Gaussian16 achieves a speed increase of 1.24 to 1.35 times compared to the AVX version of Gaussian16. Compared to SSE4 version and AVX version of Gaussian 09 (our benchmark article), compared with the effect that only speed increase of about 1.12 to 1.14 times, the AVX 2 version of Gaussian16 works very effectively. , and also the default DFT grid has been changed from FineGrid to UltraFine. On the other hand, the newly supported AVX2 version of Gaussian16 achieves a speed increase of 1.24 to 1.35 times compared to the AVX version of Gaussian16. Compared to SSE4 version and AVX version of Gaussian 09 (our benchmark article), compared with the effect that only speed increase of about 1.12 to 1.14 times, the AVX 2 version of Gaussian16 works very effectively.
|
评分 Rate
-
查看全部评分 View all ratings
|







 发表于 Post on 2018-4-16 17:23:00
发表于 Post on 2018-4-16 17:23:00


 收藏 Add to favorites
收藏 Add to favorites